There are various types of QA systems, but they can generally be grouped into two main categories: (i) open-domain QA and (ii) closed-domain QA.
Open-domain QA systems are designed to answer questions on any topic and rely on vast amounts of unstructured text data available publicly on the internet e.g., Wikipedia. In contrast, closed-domain QA systems are specialized for specific domains, such as healthcare or legal, and require a structured knowledge base for accurate responses. Another approach to QA is information retrieval (IR)-based QA, which involves retrieving relevant documents from a corpus and extracting answers from them. This method can be used in both open and closed-domain QA systems, depending on the type of corpus used.
In addition to open and closed-domain QA, there are two other types of QA tasks: extractive and abstractive. Extractive QA extract answers directly from a given text or corpus in the form of spans, while abstractive QA generate answers using natural language generation techniques, often paraphrasing or summarizing information from the text.
A detailed article on same can be explored here – https://medium.com/@shankar.arunp/augmenting-large-language-models-with-verified-information-sources-leveraging-aws-sagemaker-and-f6be17fb10a8
Steps to make a QnA bot using LLMs / Open AI
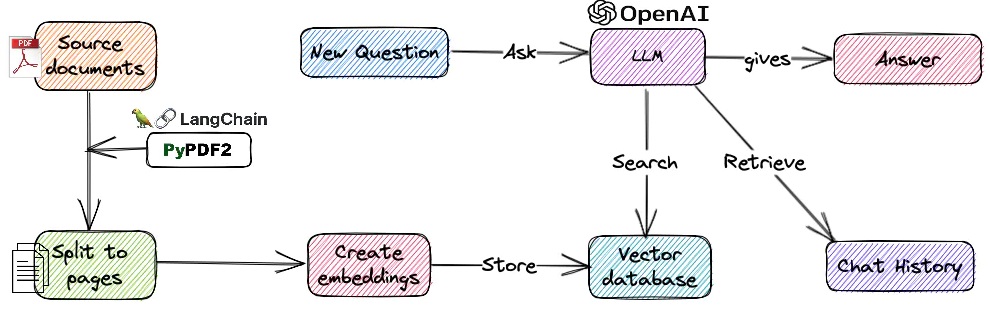
DONT JUST UPLOAD DOCUMENTS TO LLM APIs to get answers. Study how vector databases work and can help you get better performance and less tokens.
If you harness the power of LLMs with vector databases together, you can create large scale production ready bots or QnA systems. Before we see the code snippets ahead, let’s see the steps in creating QnA bot with vector databases and LLMs.
- Language Model (LLM) Initialization:
- The QnA bot uses a pre-trained language model (such as GPT-3.5) to comprehend and generate human-like text.
- The LLM is loaded and ready to process user queries.
- User Query Input:
- The bot receives a natural language question or query from the user.
- Query Preprocessing:
- The input query is preprocessed to remove any irrelevant or sensitive information and convert it into a format suitable for the next steps.
- Vector Representation:
- The preprocessed query is encoded into a vector representation using techniques like word embeddings or transformer-based embeddings (e.g., BERT, RoBERTa).
- The vector representation captures the semantic meaning and contextual information of the query.
- Vector Database Query:
- The vector representation of the user query is used to search the vector database.
- The vector database contains embeddings of relevant documents or passages, typically created using similar embedding techniques as used for the query.
- Candidate Retrieval:
- The vector database returns a set of candidate documents or passages that are potentially relevant to the user query.
- These candidates are ranked based on their similarity to the query vector.
- Answer Generation:
- For each candidate document or passage, the QnA bot retrieves the corresponding text content.
- The LLM is used to read and understand the content, extracting relevant information that can potentially answer the user’s query.
- Scoring and Ranking:
- The candidate answers are scored based on their relevance and quality.
- The scoring can be based on factors like LLM confidence in generating the answer, relevance to the user query, and other contextual information.
- Answer Selection:
- The answer with the highest score is selected as the final response to the user.
- If the confidence in the top answer is below a certain threshold, the bot may present multiple potential answers or ask for clarification.
- Response to User:
- The selected answer is presented to the user as the response to their original query.
- Feedback Loop (Optional):
- Some QnA bots may incorporate a feedback loop, allowing users to rate the accuracy and helpfulness of the provided answers.
- This feedback can be used to improve the system’s performance over time by re-ranking candidate answers or updating the vector database.
- Continual Learning (Optional):
- To keep the QnA bot up-to-date, the system can be trained with new data regularly or incrementally.
- New data may include additional user queries and corresponding correct answers.

Pingback: Exploring the Power of Language Models for QnA and Chatbots: A Comprehensive Guide | Azure, AWS, .NET , DevOps , AI/ML